Hey,
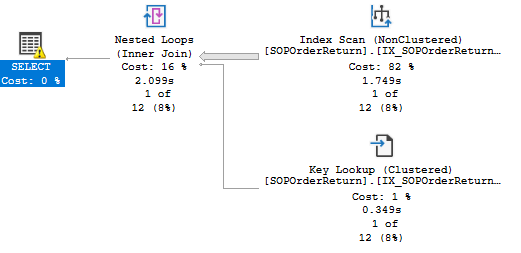
We often find searching on the sales order list painfully slow, often leading to lock errors and time outs when searching an order number,
Even when filtered down to orders from the last week it can still be super slow.
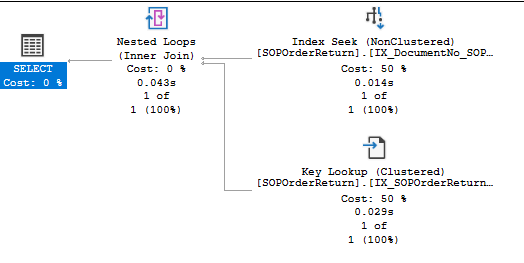
Oddly though, if we do a filter for DocumentNo equals, and put the order in there it returns the result instantly, why is there such a difference between the two?
Is there anything we can do to speed up the normal way of searching?
To give an idea about the amount of data, I have just checked and there are 74k entries in SOPOrderReturn dated this January,
Thanks