

Introduction
Most modern business applications have some sort of dashboard that displays a number of KPIs when you first sign-in. For instance here area a couple of KPIs from Sage 300 ERP:
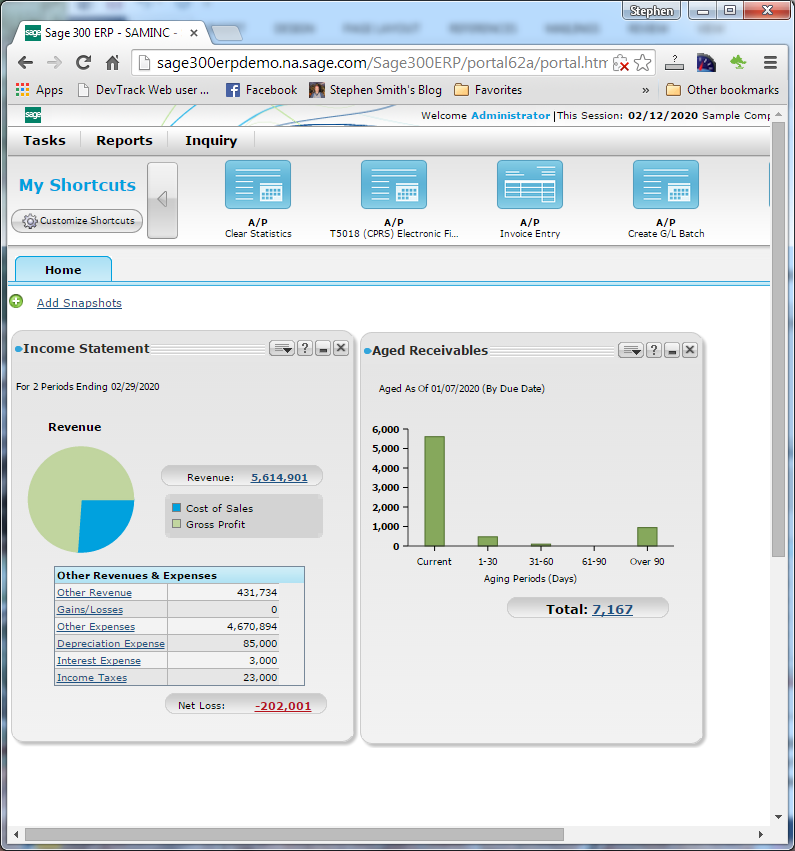
To be useful, these KPIs can involve quite sophisticated calculations to display relevant information. However users need to have their home page start extremely quickly so they can get on with their work. This article describes various techniques to calculate and present this information quickly. Starting with easy straight forward approaches progressing into more sophisticated methods utilizing the power of the cloud.
Simple Approach
The simplest way to program such a KPI is to leverage any existing calculations (or business logic) in the application and use that to retrieve the data. In the case of Sage 300 ERP this involves using the business logic Views which we’ve discussed in quite a few blog posts.
This usually gives a quick way to get something working, but often doesn’t exactly match what is required or is a bit slow to display.
Optimized Approach
Last week, we looked a bit at using the Sage 300 ERP .Net API to do a general SQL Query which could be used to optimize calculating a KPI. In this case you could construct a SQL statement to do exactly what you need and optimize it nicely in SQL Management Studio. In some cases this will be much faster than the Sage 300 Views, in some cases it won’t be if the business logic already does this.
Incremental Approach
Often KPIs are just sums or consolidations of lots of data. You cloud maintain the KPIs as you generate the data. So for each new batch posted, the KPI values are stored in another table and incrementally updated. Often KPIs are generated from statistics that are maintained as other operations are run. This is a good optimization approach but lacks flexibility since to customize it you need to change the business logic. Plus the more data that needs to be updated during posting will slow down the posting process, annoying the person doing posting.
Caching
As a next step you could cache the calculated values, so if the user has already executed a KPI once today then cache the value, so if they exit the program and then re-enter it then the KPIs can be quickly drawn by retrieving the values from the cache with no SQL or other calculations required.
For a web application like the Sage 300 Portal, rather than cache the data retrieved from the database or calculated, usually it would cache the JSON or XML data returned from the web service call that asked for the data. So when the web page for the KPI makes a request to the server, the cache just gives it the data to return to the browser, no formatting, calculation or anything else required.
Often if the cache lasts one day that is good enough, there can be a manual refresh button to get it recalculated, but mostly the user just needs to wait for the calculation once a day and then things are instant.
The Cloud
In the cloud, it’s quite easy to create virtual machines to run computations for you. It’s also quite easy to take advantage of various Big Data databases for storing large amounts of data (these are often referred to as NoSQL databases).
Cloud Approach
Cloud applications usually don’t calculate things when you ask for them. For instance when you do a Google search, it doesn’t really search anything, it looks up your search in a Big Data database, basically doing a database read that returns the HTML to display. The searching is actually done in the background by agents (or spiders) that are always running, searching the web and adding the data to the Big Data database.
In the cloud it’s pretty common to have lots or running processes that are just calculating things on the off chance someone will ask for it.
So in the above example there could be a process running at night the checks each user’s KPI settings and performs the calculation putting the data in the cache, so that the user gets the data instantly first thing in the morning, and unless they hit the manual refresh button, never wait for any calculations to be performed.
That helps things quite a bit but the user still needs to wait for a SQL query or calculation if they change the settings for their KPI or hits the manual refresh button. A sample KPI configuration screen from Sage 300 is:
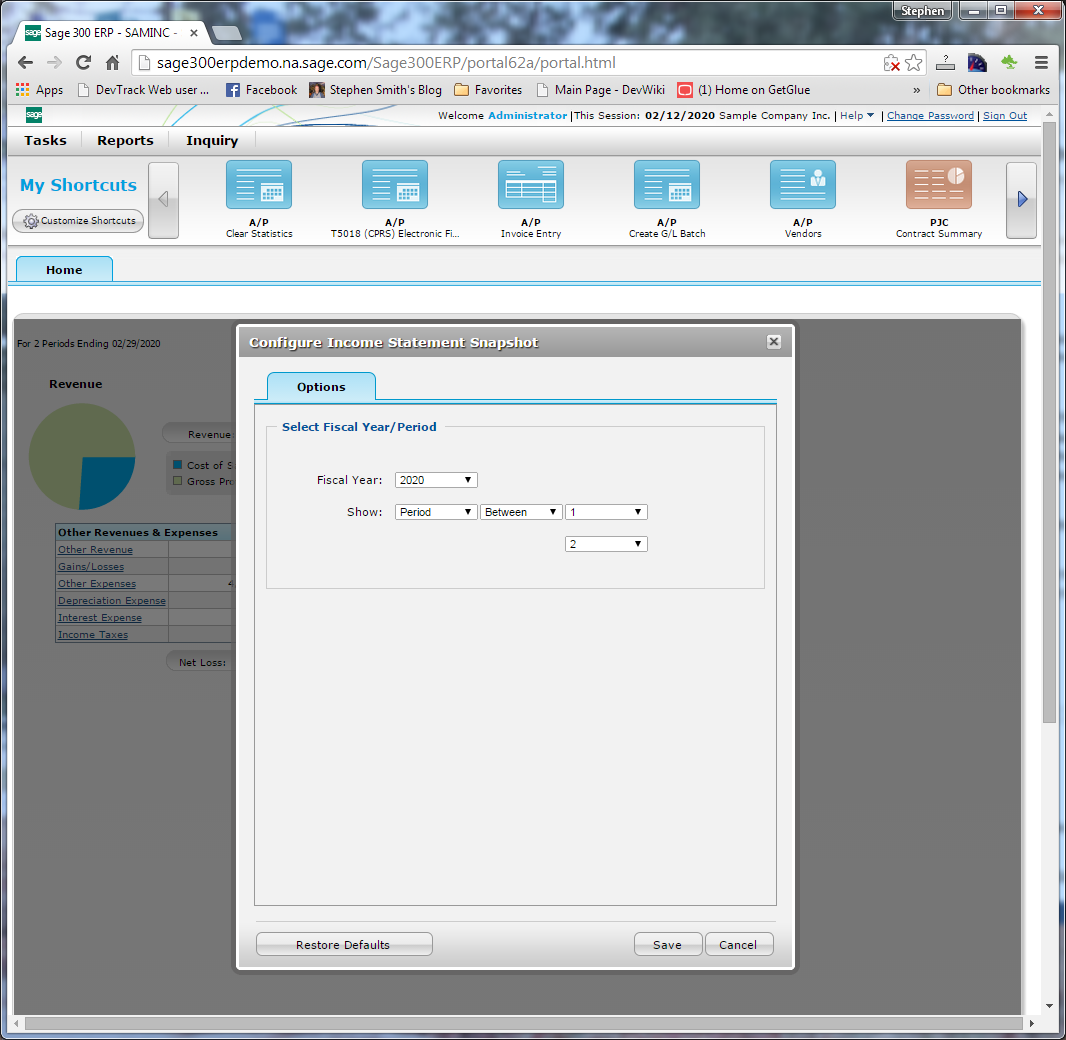
As you can see from this example there are quite a few different configuration options, but in some sense not a truly rediculous number.
I’ve mentioned “Big Data” a few times in this article but so far all we’ve talked about is caching a few bits of data, but really the number of these being cached won’t be a very large number. Now suppose we calculate all possible values for this setup screen. Use the distributed computing powe of the cloud to do the calculations and then store all the possibilities in a “Big Data” database. This is much larger than we talked about previously, but we are barely scratching the surface of what these databases are meant to handle.
We are using the core functionality of the Big Data database, we are doing reads based on the inputs and returning the JSON (or XML or HTML) to display in the widget. As our cloud grows and we add more and more customers, the number of these will increase greatly, but the Big Data database will just scale out using more and more servers to perform the work based on the current workload.
Then you can let these run all the time, so the values keep getting updated and even the refresh button (if you bother to keep it), will just get a new value from the Big Data cache. So a SQL query or other calculation is never triggered by a user action ever.
This is the spider/read model. Another would be to sync the application’s SQL database to a NoSQL database that then calculates the KPIs using MapReduce calculations. But this approach tends to be quite inflexible. However it can work if the sync’ing and transformation of the database solves a large number of queries at once. Creating such a database in a manner than the MapReduce queries all run fast is a rather nontrivial undertaking and runs the risk that in the end the MapReduces take too long to calculate. The two methods could also be combined, phase one would be to sync into the NoSQL database, then the spider processes calculate the caches doing the KPI calculations as MapReduce jobs.
This is all a lot of work and a lot of setup, but once in the cloud the customer doesn’t need to worry about any of this, just the vendor and with modern PaaS deployments this can all be automated and scaled easily once its setup correctly (which is a fair amount of work).
Summary
There are lots of techniques to produce/calculate business KPIs quickly. All these techniques are great, but if you have a cloud solution and you want its opening page to display in less that a second, you need more. This is where the power of the cloud can come in to pre-calculate everything so you never need to wait.